 HeeYeon Kwon
HeeYeon Kwon 
1장 한눈에 보는 머신러닝
1 머신러닝이란?
머신러닝
명시적인 프로그래밍 없이 컴퓨터가 학습하는 능력을 갖추게 하는 연구 분야이다 - 아서 새뮤얼
2 왜 머신러닝을 사용하는가?
많은 규칙, 유동적인 환경, 복잡한 문제, 대량의 데이터에서 통찰
1️⃣ 기존 솔루션으로는 많은 수동 조정과 규칙이 필요한 문제
스팸 필터를 예시로 들자면,
전통적인 프로그래밍 방식을 사용하면 스팸 메일 발송자가 스팸 필터에 대항하여 계속 단어를 바꾸면 영원히 새로운 규칙을 추가해야 하지만
머신러닝 기반의 스팸 필터는 사용자가 지정한 메일에 자주 나타나는 구절을 자동으로 인식하고 별도의 작업을 하지 않아도 자동으로 이 단어를 스팸으로 분류
2️⃣ 전통적인 방식으로는 해결 방법이 없는 복잡한 문제
3️⃣ 유동적인 환경: 머신러닝 시스템은 새로운 데이터에 적응 가능
4️⃣ 대량의 데이터에서 통찰 얻기
데이터 마이닝 머신러닝 기술 적용하여 대용량의 데이터를 분석하여 겉으로 보이지 않던 패턴 발견
3 머신러닝 시스템의 종류
1) 지도 학습과 비지도 학습 : 레이블 유무
1️⃣ 지도학습 알고리즘에 주입하는 훈련 데이터에 레이블이라는 원하는 답이 포함
KNN, 선형 회귀, SVM, 결정트리, 신경망
- 분류 classification
- 회귀 regression
예측변수 predicor variable라 부르는 특성feature을 사용해 중교차 가격 타깃target 수치 예측
2️⃣비지도학습 알고리즘에 주입하는 훈련 데이터에 레이블이 없음
군집, 이상치 탐지, 시각화와 차원 축소, 연관 규칙 학습
3️⃣준지도학습 일부만 데이터에 레이블이 있음
ex) 구글 포토 호스팅 서비스
4️⃣강화학습 학습하는 시스템을에이전트라고 부르며 환경을 관찰해서 행동을 실행하고 결과로 보상 /벌점을 받고 시간이 지나면 가장 큰 보상을 얻기 위해 정책이라고 부르는 최상의 전략을 스스로 학습
ex) 알파고
2) 배치 학습과 온라인 학습 : 점진적으로 학습 가능
배치학습 /오프라인학습
- 시스템이 점진적으로 학습 불가
- 가용한 데이터를 모두 사용해 훈련
-
데이터를 업데이트하고 시스템의 새 버전을 필요한 만큼 자주 훈련
ex) 은행 시간 점검하면서 이 때 업데이트
점진적 학습/온라인 학습
데이터를 순차적으로 한 개씩 또는 미니배치라 부르는 작은 묶음 단위로 주입하여 시스템을 훈련
- 시스템이 빠르게 변해야 하거나
- 데이터 양이 많거나
외부 메모리 학습 - 자원이 제한된 시스템
→ 점진적으로 학습할 수 있는 알고리즘 사용
ex) 온라인 내에서 사람들이 결제할 때마다 학습
ex) 화성 탐사 로봇
3) 사례 기반 학습과 모델 기반 학습 : 어떻게 일반화 되는가에 따라 분류
사례 기반 학습
가장 단순한 형태의 학습으로 단순히 기억하는 것
ex) 이전 스팸 메일과 유사도가 높으면 스팸으로 분류
모델 기반 학습
이 샘플들의 모델을 만들어 예측에 사용하는것
모델이 얼마나 좋은지 측정하는효용함수/적합도함수
얼마나 나쁜지 측정하는 비용함수
최적의 모델 파라미터를 찾는 것을 훈련시킨다
새로운 데이터에 모델을 적용해 추론
4 나쁜 데이터와 나쁜 알고리즘
나쁜 데이터
- 충분하지 않은 양의 훈련 데이터
- 대표성 없는 훈련 데이터
- 낮은 품질의 데이터 ( 에러, 이상치, 잡음이 많을 때)
-
관련 없는 특성
Feature Selection: 가지고 있는 특성 중 훈련에 가장 유용한 특성 선택Feature Extraction: 특성을 결합하여 더 유용한 특성 ex) PCA
나쁜 알고리즘
훈련 데이터 과대적합
훈련 데이터에 있는 잡음의 양에 비해 모델이 너무 복잡할 때
< 해결 방안 >
- 파라미터 수가 적은 모델 선택 , 특성 수 줄이기, 모델에 제약 (
규제, 학습하는 동안 적용할 규제의 양은하이퍼파라미터가 결정) - 훈련 데이터를 더 모으기
- 훈련 데이터의 잡음 줄이기 ( 이상치 제거)
훈련 데이터 과소적합
모델이 너무 단순해서 데이터의 내재된 구조를 학습하지 못할 때
< 해결 방안 >
- 모델 파라미터가 더 많은 강력한 모델을 선택
- 모델의 제약 줄이기 ( 하이퍼파라미터 감소)
- 학습 알고리즘에 더 좋은 특성을 제공 ( feature extraction)
5 테스트와 검증
훈련 데이터를 훈련 세트와 테스트 세트 두 개로 나누어 얼마나 잘 일반화 되는지 검증
새로운 샘플에 대한 오류 비율을 일반화 오차(Generalized Error) 라 하며, 테스트 세트에서 모델을 평가함으로써 이 오차에 대한 추정값을 얻음
홀드아웃 검증 훈련 세트의 일부를 떼어내고(validation set, dev set)
훈련세트에서 다양한 하이퍼파라미터 값을 가진 모델을 훈련 후 검증세트에서 가장 높은 성능을 갖는 모델을 선택
교차검증 cross validation 작은 검증세트를 여러개 사용하여 반복적인 검증 수행
검증세트마다 나머지 데이터에서 훈련한 모델을 해당 검증 세트에서 평가하여 평균내어 성능 측정
훈련-개발 세트 train-dev set 웹 사진 일부를 떼어 만들어서 검증 → 모델 잘 작동시 훈련세트에 과대적합 X
웹 사진을 앱 사진처럼 전처리 하는 방식으로 훈련 가능
6장 결정 트리(Decision Tree)
일련의 분류 규칙을 통해 데이터를 분류,회귀하는 지도 학습 모델 중 하나이며,
결과 모델이 Tree 구조를 가지고 있기 때문에 Decision Tree라는 이름을 가집니다.

5 CART 훈련 알고리즘
사이킷런은 CART(classification and regression tree, 분류와 회귀 나무) 알고리즘을 이용하여 의사결정나무를 훈련시킨다. CART 알고리즘의 작동법은 다음과 같다.
-
탐욕적 알고리즘(greedy algorithm)을 이용하여 아래 비용함수를 최소화 하는 특성 𝑘와 해당 특성의 임곗값 𝑡𝑘을 결정한다.여기서

- 𝐺left(𝐺right)는 왼편(오른편) 부분집합의 지니 불순도
- 𝑚left(𝑚right)는 왼편(오른편) 부분집합의 샘플 수
- 𝐽(𝑘,𝑡𝑘)이 작을 수록 지니 불순도가 보다 낮은 두 개의 부분집합으로 분할할 수 있게 된다. 따라서 탐욕적 알고리즘은 해당 마디에 포함된 샘플을 지니 불순도가 가장 낮은, 즉, 가장 순수한(pure) 두 개의 부분집합으로 분할한다.
- 이렇게 나누는 과정은
max_depth깊이에 다다르거나 불순도를 줄이는 분할을 더 이상 찾을 수 없을 때, 또는 다른 규제의 한계에 다다를 때 까지 반복된다.
사이킷런의 의사결정트리에 사용된 알고리즘의 복잡도는 (샘플을 미리 퀵정렬 시켰다고 가정했을 때) 각 마디에서는 𝑂(𝑛⋅𝑚log(𝑚)) 이며,
훈련 세트를 미리 퀵정렬 시키려면 presort=True 옵션을 이용하념 된다. 하지만 훈련 세트가 크면 이 방식은 속도가 늦어진다. 이유는 퀵정렬 자체의 복잡도가 𝑂(𝑚log𝑚) 샘플 수가 크면 상당히 느려지기 때문이다.
아무런 규제가 없다면 의사결정나무를 완성하는 데 걸리는 시간은 대략 𝑂(𝑛⋅𝑚2log(𝑚)) 이다.
여기서 𝑛은 특성 수, 𝑚은 샘플 수를 가리킨다. (참조: 사이킷런 의사결정나무)
의사결정나무가 완성이 되었다면, 예측에 필요한 시간은 보통 특성 수와 상관없이 𝑂(log𝑚)으로 매우 빠르다.
👍🏻 장점
- 이해하고 해석하기 쉬움
- 범주와 연속형, 분류와 회귀 모두 예측 가능
👎🏻 단점
- 계단 모양의 결정 경계를 만들어 훈련 세트의 회전에 민감
- 훈련 데이터에 있는 작은 변화에도 매우 민감
7장 앙상블 학습과 랜덤 포레스트
개요
연습문제
- 배깅 앙상블의 훈련을 여러 대의 서버에 분산시켜 속도를 높일 수 있을까요? 페이스팅 앙상블, 부스팅 앙상블, 랜덤 포레스트, 스태킹 앙상블의 경우는 어떨까요?
- 배깅/페이스틍 기반 앙상블의 각 예측기는 독립적이므로 여러 대의 서버에 분산하여 앙상블의 훈련 속도를 높일 수 있다.
- 부스팅 앙상블의 예측기는 이전 예측기를 기반으로 만들어지기 때문에 훈련이 순차적이어야하고, 여러 대의 서버에 분산해서 얻을 수 있는 이득이 없다.
- 스태킹 앙상블의 경우 한 층의 모든 예측기가 각각 독립적이므로 여러대의 서버에서 병렬로 훈련될 수 있다. 하지만 한 층에 있는 예측기들은 이전 층의 예측기들이 훈련된 후에 훈련될 수 있다.
- 무엇이 엑스트라 트리를 일반 랜덤 포레스트보다 더 무작위하게 만드나요? 추가적인 무작위성이 어떻게 도움이 될까요? 엑스트라 트리는 일반 랜덤 포레스트보다 느릴까요, 빠를까요?
- 랜덤 포레스트에서 트리가 성장할 때 각 노드에서 특성의 일부를 무작위로 선택해 분할에 사용한다. 가능한 최선의 임계점을 찾는게 아니라, 각 특성에 대해 랜덤한 임계점을 사용한다, 이 추가적인 무작위성은 규제처럼 작동한다. 가능한 최선의 임계점을 찾는게 아니라 랜덤포레스트보다 훈련이 더 빠르다.
- Adaboost(아다부스트)가 과소적합되었다면 어떤 매개변수를 어떻게 바꾸어야 할까요?
- 예측기의 수를 증가시키거나, 기반 예측기의 규제 하이퍼파라미터를 감소시켜 볼 수 있다. 또한 학습률을 약간 증가시켜 볼 수 있다.
- 그래디언트 부스팅이 훈련 데이터에 과대적합되었다면 학습률을 높여야 할까요, 낮춰야 할까요?
- 학습률을 감소시켜야한다 ( 예측기 수가 너무 많으면 ) 알맞은 개수를 찾기 위해 조기 종료 기법을 사용할 수 있다.
[기타 문제]
- 정확히 같은 훈련 데이터로 다섯 개의 다른 모델을 훈련시켜서 모두 95%의 정확도를 얻었다면 이 모델들을 연결하여 더 좋은 결과를 얻을 수 있을까요? 가능하다면 어떻게 해야 할 까요? 그렇지 않다면 왜일까요?
- 앙상블을 만들어 더 나은 결과를 기대할 수 있다. 모델이 서로 다르다면 더 좋다. 그리고 다른 훈련 샘플에서 훈련되었다면 더욱 좋다. 그렇지 않아도 모델이 서로 많이 다르면 여전히 좋은 결과를 냄!
- 직접 투표와 간접 투표 분류기 사이의 차이점은 무엇일까요?
- 직접 투표 분류기는 횟수를 중요시하여, 가장 많은 투표를 얻은 클래스를 선택. (다수결)
- 간접 투표 분류기는 각 클래스의 평균적인 확률 추정값을 계산해서 가장 높은 확률을 가진 클래스를 고름. 이 방법은 신뢰가 높은 투표에 더 가중치를 주고 종종 더 나은 성능을 낸다. (확률 구할 수 있는 경우만 사용 가능)
- oob 평가의 장점은 무엇인가요?
- 배깅 앙상블의 각 예측기가 훈련에 포함되지 않은 샘플을 사용해 평가된다. 이는 추가적인 검증 세트가 없어도 편향되지 않게 앙상블을 평가하도록 도와준다. 그러므로 훈련에 더 많은 샘플을 사용할 수 있어서 앙상블의 성능은 조금 더 향상 될 것.
😀 Voting

Hard Voting (직접 투표)
전체 훈련 세트 하나에 대해 여러 개의 분류기를 훈련시킨 후 각 분류기의 예측을 모아서 가장 많이 선택된 클래스로 예측하는 방법으로, 이렇게 다수결 투표로 정해지는 분류기를 말한다.
- 다수결 투표 분류기가 앙상블에 포함된 가장 뛰어난 개별 분류기보다 정확도가 높을 수 있음
- 각 분류기가 weak learner*일지라도 충분히 많고 다양하다면 앙상블은 strong learner(강한 학습기)가 될 수 있다.
- Weak learner : 랜덤 추측보다 조금더 높은 성능을 내는 분류기
- Why? 큰수의 법칙 때문. (모든 분류기가 독립이고 오차에 상관관계가 없는 경우 가정)
- 큰수의 법칙
> 어떤 시행에서 사건 A가 일어날 수학적 확률이 p일 때 n번의 독립시행에서 사건 A가 일
어나는 횟수를 X라 하면, 아무리 작은 양수 h를 택하더라도 n을 충분히 크게 하면
$P{|X_n-p|<h}$는 1에 가까워진다.
>
Soft Voting (간접 투표)
모든 분류기가 클래스의 확률을 예측할 수 있으면 개별 분류기의 예측을 평균내어 확률이 가장 높은 클래스를 예측하는 것을 Soft Voting이라 한다.
- 확률이 높은 것에 비중을 더 두기 때문에 hard voting 방식보다 성능이 높다.
Bagging과 Pasting
전체 훈련 세트의 서브셋을 무작위로 구성하여 하나의 분류기를 각기 다르게 학습시키는 방법이다.

Bagging (배깅, bootstrap aggregation의 준말)
훈련 세트에서 중복을 허용하는 샘플링하는 방식이다.
Pasting (페이스팅)
훈련 세트에서 중복을 허용하지 않고 샘플링하는 방식이다.
Bagging & Pasting의 특징
- 최종 예측은 Classification(분류) 일 땐, Hard Voting Classifier처럼 통계적 최빈값를 따르고, Regression에 대해선 평균을 계산한다.
- 원본 데이터 전체이 아닌, subset을 학습한 개별 분류기는 크게 편향이 되어있지만(Underfit), 수집 함수를 통과하면 편향(Bias)과 분산(variance)이 모두 감소한다.
- 하나의 예측기를 훈련시킬 때보다, 분산은 줄어든다.
-
병렬로 학습 및 병렬로 예측을 수행할 수 있다는 장점 존재
- Bootstraping 특성 상 subset에 다양성을 증가시키므로 배깅이 페이스팅보다 편향이 좀 더 높다.
- 다양성을 추가한다는 것은 예측기 간 상관관계를 줄이므로 앙상블의 분산을 감소시킨다.
- 전반적으로 Bagging이 성능이 높은 점에서 더 많이 선호한다.
기타 사항
- oob (out-of-bag sample) : 배깅에서 선택되지 않은 샘플로 oob sample은 valid set로 대신 사용할 수 있음.
- 특성 샘플링 : 특성까지 샘플링하는 방식 → 편향을 늘리는 대신 분산을 낮춤
- 랜덤 패치 방식 (Random patches method) : 훈련 샘플 - 샘플링 / feature - 샘플링
- 랜덤 서브스페이스 방식(Random Subspace method) : 훈련 샘플 - 전체 / feature - 샘플링
Random Forests
Random Forests(랜덤 포레스트)는 Bagging 혹은 Pasting을 적용한 Decision Tree의 앙상블이다. (여러 개의 작은 Decision Tree를 만드는 것)


- Random Forest 알고리즘은 트리의 노드를 분할할 때, 전체 feature 중 최선의 feature를 찾는 대신 무작위로 선택한 feature 후보들 중 최적의 feature를 찾음으로써 무작위성을 더 주입한다.
- 최적의 Feature를 찾는다 = 부트스트랩과 특성 샘플링
- 최적의 임계점(split point)을 찾는다 = CART
- 이러한 무작위성은 트리를 더욱 다양하게 만들고, 이러한 다양성은 편향을 낮추지만 분산을 낮추어 더 훌륭한 모델을 만들어낸다.
Random Forest 기타
- Feature Importance (특성 중요도) 파악 용이 (6장 참고)
-
Extratree

- 최적의 임계점을 찾는 대신 후보 Feature를 사용해 무작위로 분할한 후 최상의 분할을 선택 → Random Forest보다 빠른 장점이 존재
- VS Random Forest (핸즈온 X)
- Random Forest는 여러 개의 Decision Tree, 엑스트라 트리는 여러 개의 Extra Tree 배깅
- Bootstrap 사용 여부 : 랜덤 포레스트는 Bootstrap 샘플링을 사용하지만 엑스트라 트리는 Bootstrap=False가 기본값
- 노드 분할 방법 : 랜덤 포레스트는 최적의 분할, 엑스트라 트리는 무작위 분할 후 선택
- In ExtraTrees, the split point for each node in a decision tree is selected at random, rather than selecting the best split point based on a specific criterion like Gini impurity or information gain, which is used in other decision tree algorithms like CART (Classification and Regression Trees) or ID3 (Iterative Dichotomiser 3).
- 편향과 분산 차이 : 엑스트라 트리는 모든 데이터를 사용하기 때문에 랜덤 포레스트에 비해 편향이 감소함. 무작위 선택의 영향으로 분산 또한 감소
- 속도 : 엑스트라 트리는 최적의 분할을 계산하지 않아서 속도가 빠름
👩🏻💻 Boosting
Boosting(부스팅)은 약한 학습기를 여러 개 연결하여 강한 학습기를 만드는 앙상블 방법을 말한다. 여기에는 AdaBoost와 Gradient Boosting이 있다.
AdaBoost (Adaptive Boosting)
AdaBoost는 이전 모델이 Underfitting했던 training data의 가중치를 더 높이며 새로운 모델을 만든다. 이렇게 하면 새로운 예측기는 학습하기 어려운 샘플에 점점 더 맞춰지게 된다.

- AdaBoost Classifier를 만들 때 먼저 Decision tree와 같은 첫 번째 Classifier를 Training set에서 훈련시키고 예측을 만든다. 그 다음 알고리즘이 잘못 분류했던 Training data의 가중치를 높인다.
- 다음 Classifier에서는 업데이트된 가중치로 Training set을 학습하고 예측하고, 나머지 과정은 반복되는 식이다.
Gradient Boosting
Gradient Boosting도 이전까지의 오차를 보정한 예측기가 순차적으로 앙상블에 추가된다. 다만 AdaBoost처럼 데이터의 가중치를 갱신하는 대신 이전 예측기가 만든 잔여 오차(residual error)를 새로운 예측기에 학습시킨다.
- 원리 파악을 위한 구현 예시
from sklearn.tree import DecisionTreeRegressor
# 첫번째 모델 학습
tree_reg1 = DecisionTreeRegressor(max_depth=2, random_state=42)
tree_reg1.fit(X, y)
# 첫번째 모델의 오차에 대해 두번째 모델로 학습
y2 = y - tree_reg1.predict(X) # residual errors
tree_reg2 = DecisionTreeRegressor(max_depth=2, random_state=42)
tree_reg2.fit(X, y2)
# 두번째 모델의 오차에 대해 세번째 모델로 학습
y3 = y2 - tree_reg2.predict(X) # residual error
tree_reg3 = DecisionTreeRegressor(max_depth=2, random_state=42)
tree_reg3.fit(X, y3)
# 각 모델의 합이 최종 결과
y_pred = sum(tree.predict(X_new) for tree in (tree_reg1, tree_reg2, tree_reg3))
- 트리가 추가될수록 앙상블의 예측이 좋아지는 것을 볼 수 있음.

- 트리가 너무 많이 추가될 시 overfiting의 위험성이 커짐 → early stoping 필요함

❤️ Stacking
앙상블에 속한 모든 예측기의 예측을 취합하는 간단한 함수(Hard Voting 등)을 사용하는 대신, 취합하는 모델 자체를 훈련 시키고자 하는 방법이다.
새로운 샘플에 회귀 작업을 수행하는 앙상블 (블렌딩 예측기를 통한 취합)
- 세 예측기는 각각 다른 값을 예측하고, 마지막 예측기(블렌더)가 이 예측을 입력으로 받아 최종 예측을 만든다.
- 각주 : 분류의 경우 Blending을 로지스틱 회귀로 할 수 있음.

- 마지막 예측기(블렌더)를 학습시키는 일반적인 방법은 홀드 아웃(hold-out) 세트를 사용한다.
- 먼저 training set을 2개의 subset으로 나눈다.
- subset1은 첫번째 레이어의 예측기들을 훈련시키는데 사용한다.
- 훈련된 첫번째 레이어의 예측기로 subset2에 대한 예측을 생성 (첫 번째 레이어 훈련하기)


-
블렌더를 여러 개 훈련시킬 수 있다.

- 훈련 세트를 세 개의 subset으로 나눈다.
- 첫 번째 세트는 첫 번째 레이어를 훈련
- 두 번째 세트는 첫 번째 레이어의 예측기로 두 번째 레이어를 훈련시키기 위한 훈련 세트를 만드는 데 사용
- 세 번째 세트는 두 번째 레이어의 예측기로 세 번째 레이어를 훈련시키기 위한 훈련 세트를 만드는 데 사용
- 작업이 끝나면 각 레이어를 차례대로 실행해 새로운 샘플에 대한 예측을 만들 수 있다.
- Voting
- Boosting
- Stacking




8장 차원 축소
차원의저주
특성 수가 많아지면 많은 요소에 민감하게 반응하게 되어 과대적합 위험이 커진다. 이것을 차원의 저주라 부른다.
*고차원의 특성
사람에게 친숙한 1차원~ 3차원 공간과 100차원, 1,000 차원, 10,000 차원 공간은 성질이 많이 다르다.
1) 2차원 상의 단위면적(1×1 크기의 사각형) 안에 있는 점을 무작위로 선택해서 경계선에서 0.001 이내에 위치할 확률은 0.4%. 반면에 10,000 차원 상의 단위 초입방체(unit hypercube)의 경우 이 가능성이 99.999999% 이상이다.
= 초입방체에서 두 점은 대부분 경계선과 매우 가까이 있다
2) 3차원 단위 육면체 내에서 임의의 두 점 사이의 거리는 평균 0.66인 반면에, 1백만 차원에서의 단위 초입방체 내에서의 두 점 사이의 평균 거리는 428.25이다. = 초입방체에서 두 점은 거리가 멀다
→ 고차원 공간에서 두점은 경계 가까이 위치해서 거리가 너무 멀다.
따라서 새로운 샘플도 기존의 훈련 샘플과의 거리도 너무 멀 가능성이 크다. 이는 새로운 샘플에 대한 예측을 위해 너무 멀리 떨어져 있는 값들을 기준으로 정해야 함을 의미한다. 즉, 더 멀리 떨어져 있는 점들을 기준으로 해야하면서 동시에 많은 요소들을 함께 고려해야 하기에 예측이 훨씬 불안정해진다.
*차원의 저주 해결 방법 1 ) 매우 큰 훈련 세트
매우 큰 훈련 세트를 사용하여 밀도를 높이는 방법이 있는데, 이것은 현실적으로 불가능하거나 바람직하지 않다.
- 훈련 세트가 너무 크면 학습이 제대로 이루어지지 않거나 너무 오래 걸린다.
- 엄청 큰 훈련 세트가 필요한데 예를 들어, 100차원 상에서 단위 초입방체 내에서 임의의 두 샘플 사이의 거리를 0.1 이하로 만들려면 관측 가능한 우주에 있는 원자 수 보다 많은 훈련 샘플이 필요하다. 그 만큼의 데이터를 모을 수도 없을 뿐더러, 주어졌다 하더라도 학습을 시킬 수 없을 것이다.
*차원의 저주 해결 방법 2) 차원 축소 기법
차원 축소 하기 전 고려사항
차원 축소로 인해 경우에 따라 학습된 모델의 성능이 나빠질 수 있다. 이런 경우를 대비해 먼저 원본 데이터셋으로 훈련을 시도한 후에 차원 축소 여부를 결정해야 한다.
차원축소를 하는 이유
1) 특성 수를 줄이는 차원 축소를 실행하면 특성 정보가 조금 유실되어 학습 결과에 영향을 줄 수도 있지만 보다 빠른 학습이 이루어지거나, 이전엔 불가능했던 학습이 가능해질 수도 있다. 하지만 일반적으로는 훈련 속도만 빨라진다.
2) 데이터 시각화
특성 수를 둘 또는 셋으로 줄이면 시각화를 이용하여 고차원 훈련 세트를 군집 등의 패턴을 보이도록 유도할 수 있어서 훈련 데이터셋에 대한 중요한 직관을 얻을 수 있다.
차원 축소 기본 아이디어
1) 투영(Projection)



n 차원 상의 훈련 샘플이라 하더라도 많은 경우 모든 차원에 균일하게 퍼져 있지는 않다.
예를 들어, MNIST 손글씨 샘플의 경우 이미지 테두리 근처의 특성은 흰색으로 변하지 않는다.이때, 거의 변화가 없는 특성을 무시한다면 MNIST의 샘플을 저차원 부분공간(subplace)의 훈련 샘플로 다룰 수 있다.
2) 다양체 학습(Manifold Learning)


많은 경우 스위스롤 데이터셋처럼 부분 공간이 뒤틀리거나 휘어 있기도 하다. 그냥 평면에 투영시키면 서로 뭉개지기 때문에 스위스롤을 펼쳐서 2D로 얻는 것이 우리가 원하는 것.
스위스 롤은 매니폴드의 한 예시이고, 2D 매니폴드는 고차원 공간에서 휘어지거나 뒤틀린 모양이다.
많은 축소 알고리즘이 훈련 샘플이 놓여 잇는 매니폴드를 모델링하는 식으로 작동하고
매니폴드 가정/매니폴드 가설
이것은 대부분 실제 고차원 데이터셋이 더 낮은 저차원 매니폴드에 가깝게 놓여 있다는 가정.
MNIST 데이터셋으로 예시를 들면,
숫자 이미지를 만들 때 가능한 자유도는 아무 이미지나 생성할 때의 자유도보다 훨씬 낮아서 이런 제약은 데이터셋을 저차원의 매니폴드로 압축할 수 있도록 도와준다.
+암묵적으로 다른 가정과 병행
분류나 회귀등의 작업이 매니폴드 공간에 표현되면 더 간단해질 것이란 가정
→ 하지만 항상 유효한 것은 아니다 ! 전적으로 데이터셋에 따라 다르다
차원 축소 알고리즘
주성분 분석 PCA(principal component anaylsis)데이터에 가장 가까운 초평면을 정의한 다음, 데이터를 이 평면에 투영
① 분산 보존 : 올바른 초평면 선택하기
정보가 가장 적게 손실되도록 훈련세트에서 분산이 최대로 보존되는 축을 선택
= 원본 데이터셋과 투영된 것 사이의 평균 제곱 거리를 최소화하는 축
②주성분(principal component PC) : 직교하는 축 찾기
훈련세트에서 분산이 최대인 축을 찾은 후 첫번째 축에 직교하고 남은 분산을 최대한 보존하는 두 번째 축을 찾고 i 번째 축을 이 데이터의 i 번째 주성분라고 한다.
훈련 세트의 주성분을 찾는 방법은? 특잇값 분해 singular value decomposition(SVD)
③ d차원으로 투영하기
주성분을 모두 추출한 후 처음 d개의 주성분으로 정의한 초평면에 투영하여 데이터셋의 d차원으로 축소시킬 수 있다.
# 데이터셋 차원 줄이기
from sklearn.decomposition import PCA
pca = PCA(n_components = 2)
X2D = pca.fit_transform(X)
# 설명된 분산의 비율 확인하기
pca.explained_variance_ratio_
>>> array([0.84248607, 0.14631839]) # 데이터셋 분산의 84.2% 첫번째 pc, 14.6% 두번째 pc -> 남은 pc는 1.2%
④ 적절한 차원수 선택하기
1) 충분한 분산 예를 들어 95% 될때까지 더해야 할 차원 수를 선택
# 필요한 최소한의 차원 수 계산
pca = PCA()
pca.fit(X_train)
cumsum = np.cumsum(pca.explained_variance_ratio_)
d = np.argmax(cumsum >= 0.95) + 1
# 설명된 분산을 차원 수에 대한 함수로 그리기
2) 데이터 시각화를 위해 차원을 2,3개로 줄이기
커널 PCA
지역 선형 임베딩 Locally Linear Embedding LLE각 훈련 샘플이 가장 가까운 이웃에 얼마나 선형적으로 연관되어 있는지 측정하고 이 관계가 가장 잘 보존되는 훈련 세트의 저차원 표현 찾음 투영에 의존하지 않는 매니폴드 학습
CH9 비지도학습
1 군집
- 비슷한 샘플을 군집화 한다
- 데이터분석, 고객분류, 추천 시스템, 검색 엔진, 이미지 분할, 준지도 학습, 차원축소에 활용가능
- 고객분류 : 고객을 구매 이력이나 웹사이트 행동을 기반으로 클러스터링 진행하여 고객그룹 생성하여 사용자가 좋아하는 컨텐츠를 추천하는 추천시스템 생성
- 데이터 분석 : 새로운 데이터셋을 분석할때 군집알고리즘 실행하여 각 클러스터 따로 분석
- 차원축소 기법 : 한 데이터셋에 군집알고리즘 적용하면 각 클러스터에 대한 샘플의 affinity(친화성)측정 가능, 그 후 각 특성벡터를 클러스터의 친화 벡터로 바꿈 EX) k개의 클러스터가 있으면 벡터를 k차원으로 바꿈
- 이상치 탐지 : 모든 클러스터에 친화성이 낮은 샘플은 이상치임
- 준지도 학습 : 레이블된 샘플이 적다면 군집을 수행하고 동일한 클러스터에 있는 모든 샘플에 레이블링할 수 있다.
- 검색 엔진 : 비슷한 이미지 클러스터 추천
- 이미지 분할 : 색을 기반으로 픽셀을 클러스터로 모아서 각 픽셀을 해당 클러스터의 평균 색으로 바꾸어 이미지에 있는 색상의 종류를 줄인다 → 물체의 윤곽 감지가 쉬움 → 물체 탐지, 추적 시스템에 활용
1) K평균 : 데이터를 k개의 군집으로 묶는 알고리즘
- k평균 알고리즘
- 중심점을 랜덤하게 초기화 → 중심점에 가까운 샘플에 레이블 할당한다 → 모든 주어진 데이터의 군집 배정이 끝나면 중심점으로 재설정 → 데이터 할당 반복 → 중심점 이동이 없을때까지
- 중심점을 잘 맞추는 것이 중요함
- k평균 ++ 알고리즘
- 최적의 솔루션을 찾기위해 다른 중심점과 거리가 먼 중심점을 선택하는 방법을 채택
- 무작위로 1개의 중심점 선택 → 샘플과의 거리로 만든 확률분포를 활용하여 멀리 떨어진 샘플을 다음 중심적으로 선택할 가능성을 높임 → k개의 중심점이 선택될때까지 반복
- 최적의 클러스터 갯수 찾기
-
이너셔 : 각 데이터들과 가장 가까운 중심점 사이의 제곱 거리 합

- 이너셔가 꺾이는 지점을 선택
-
실루엣 점수 : 모든 데이터에 대한 실루엣 계수의 평균
\[(b-a) / max(a,b)\]a : 동일한 클러스터에 있는 다른 샘플까지 평균 거리(클러스터 내부의 평균 거리)
b : 가장 가까운 클러스터까지 평균 거리(가장 가까운 클러스터 샘플까지 평균거리)
-
1에 가까우면 자신의 클러스터 안에 속해있다, -1에 가까우면 샘플이 잘못된 클러스터에 할당되어 있다.

-
- 실루엣 다이어그램 : 모든 데이터의 실루엣 계수를 할당된 클러스터와 계숫값으로 연결
- 너비가 넓을수록 좋다
-
수직선 : 각 클러스터에 해당하는 실루엣 점수 - 이 점수보다 낮은 점수면 나쁜 클러스터, k = 3, 6

-
- K평균의 장단점
- 장점 : 속도가 빠르고 확장이 빠름
- 단점 : 최적의 솔루션을 위해 알고리즘 여러번 사용해야함. 클러스터 갯수를 설정해야함, 클러스터의 크기나 밀집도가 다르거나 원형이 아닐때 작동하지 않음
- 군집을 사용한 이미지 분할
- 이미지 분할 : 이미지를 세그먼트 여러개로 분할하는 작업 EX) 자율주행에서 보행자로 분류
-
모든 초록색을 하나의 컬러 클러스터 분류

- 군집을 사용한 전처리 : 클러스터 갯수를 임의로 할당하여 모델 X변수로 사용
2) DBSCAN
- 알고리즘이 각 데이터에서 특정 거리 내에 샘플이 몇개 놓여있는지 센다. → 최소 데이터 갯수개의 샘플이 있다면 핵심샘플로 간주 → 핵심샘플의 이웃의 이웃으로 계속해서 클러스터 형성, 핵심 샘플 아니고 이웃도 아닌 샘플은 이상치로 판단
- 장점 : 클러스터의 모양과 개수에 상관없이 감지할 수 있다. 이상치에 안정적임
- 단점 : 클러스터 간의 밀집도가 다르면 모든 클러스터를 올바르게 잡기 힘들다, 계산복잡도는 O(mlogm)이고 샘플갯수에 대해 선형적 증가, 그러나 사이킷 런에서는 eps 가 커지면 O(M^2)만큼 메모리가 필요
3) 병합 군집
-
클러스터 계층을 밑바닥부터 위로 쌓아 구성

- 지정해둔 클러스터 개수가 되면 병합 끝
- 계층적 군집
4) BIRCH
- 대규모 데이터셋을 위해 고안
- 특성 개수가 너무 많지 않다면 배치 k평균보다 빠르고 비슷한 결과를 만듬
5) 평균-이동
- 각 샘플을 중심으로 하는 원을 그림 → 원마다 안에 포함된 모든 샘플의 평균을 구함 → 원의 중심을 평균점으로 이동 → 원이 움직이지 않을때까지 반복
6) 유사도 전파
- 샘플은 자신을 대표할 수 있는 비슷한 샘플에 투표함, 알고리즘이 수렴하면 각 대표와 투표한 샘플이 클러스터 형성, 대규모 데이터 셋에 적합하지 않음
7) 스펙트럼 군집
- 샘플 사이의 유사도 행렬을 이용하여 저차원 임베딩을함(차원 축소) → 저차원 임베딩에서 군집 알고리즘 사용
2 이상치 탐지
- 정상 데이터가 어떻게 보이는지 학습하여 비정상 샘플 탐지
- 제조라인에서 결함제품 감지
- 시계열 데이터에서 새로운 트렌드 발견
3 밀도추정
- 데이터셋 생성 확률 과정의 확률밀도 함수 추정
- 이상치 탐지에 활용
4 가우시안 혼합 : 이상치 탐지, 밀집도 추정에 활용 가능
- 데이터가 알려지지 않은 여러개의 혼합된 가우시안 분포에서 생겼다고 가정하는 확률 모델


- m, k 번 플레이트 내용이 반복 → m개의 확률변수 x, k개의 평균, 공분산 행렬 존재
- 하나의 가중치 파라메터 존재
- 각 변수 z는 가중치 파라메터를 갖는 범주형 분포에서 샘플링한다. 각 변수 x는 클러스터 z로 정의된 평균과 공분산 행렬을 사용해 정규분포에서 샘플링
- 확률 변수 z의 확률 분포는 가중치 파라메터에 의존한다.
- 데이터 셋 X가 주어지면 가중치 파라메터와 전체 분포의 파라메터에서 평균, 공분산 k개 추정한다.
- 가우시안 혼합모델은 생성모델으로 모델에서 새로운 샘플을 만들 수 있다.
- 가우시안 혼합 모델은 데이터가 주어지면 데이터의 밀도를 추정할 수 있다.
1) 가우시안 혼합을 사용한 이상치 탐지
- 밀도가 낮은 지역에 있는 데이터는 이상치로 판단.
2) 클러스터 개수 선정하기
- BIC, AIC 와 같은 이론적 정보 기준 사용

-
m : 샘플의 갯수, p : 모델이 학습할 파라미터 개수, L : 가능도 함수의 최대값

3) 베이즈 가우시안 혼합모델
-
자동으로 불필요한 클러스터 개수 제거한다.

- 알파(농도)가 크면 가중치값이 0에 가깝게 되고 SBP는 많은 클러스터를 만든다.
- 알파(농도)가 작으면 1에 가깝게 되고 몇개의 클러스터만 만들어짐
- 위샤트 분포를 사용해 공분산 행렬 샘플링, d, v 파라메터가 클러스터 분포모양 제어
4) 가우시안 혼합모델 장단점
- 장점 : 타원형 클러스터에 잘 작동한다. 이상치 감지에 좋음
- 단점 : 다른 모양을 가진 데이터셋에 훈련하면 나쁜 결과를 얻는다.
5 이상치 탐지와 특이치 탐지를 위한 다른 알고리즘
- PCA
- Fast-MCD : 데이터가 하나의 가우시안 분포에서 생성되었다고 가정함, 이상치 감지에 유용하다. 데이터셋 정제할 때 사용
- 아이솔레이션 포레스트 : 고차원 데이터셋에서 이상치 감지를 위한 알고리즘, 무작위로 성장한 결정트리로 구성된 랜덤 포레스트를 생성하여 데이터를 분리되어 모든 데이터가 다른 데이터로 분리될때까지 진행한다. 이때, 이상치는 다른 데이터와 멀리 떨어져있으므로 낮은 단계에서 이상치 구분 가능
- LOF : 주어진 데이터 주위의 밀도와 이웃 주위의 밀도 비교
- one-class SVM : 특이치 탐지에 잘 맞음
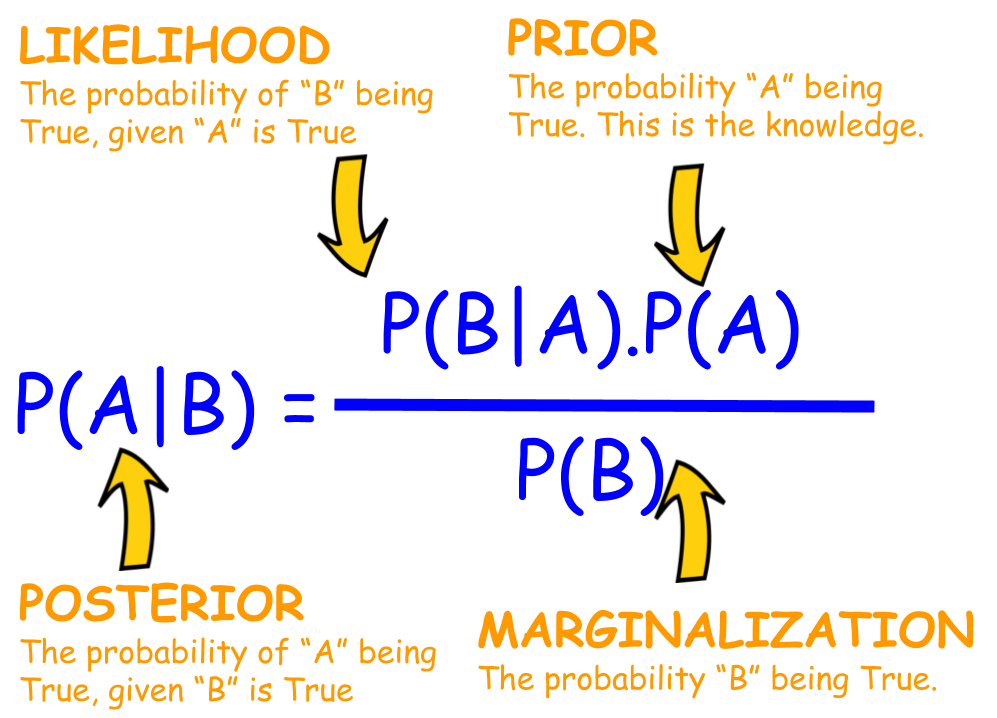 Bayes Theorem
Bayes Theorem