HeeYeon Kwon
HeeYeon Kwon 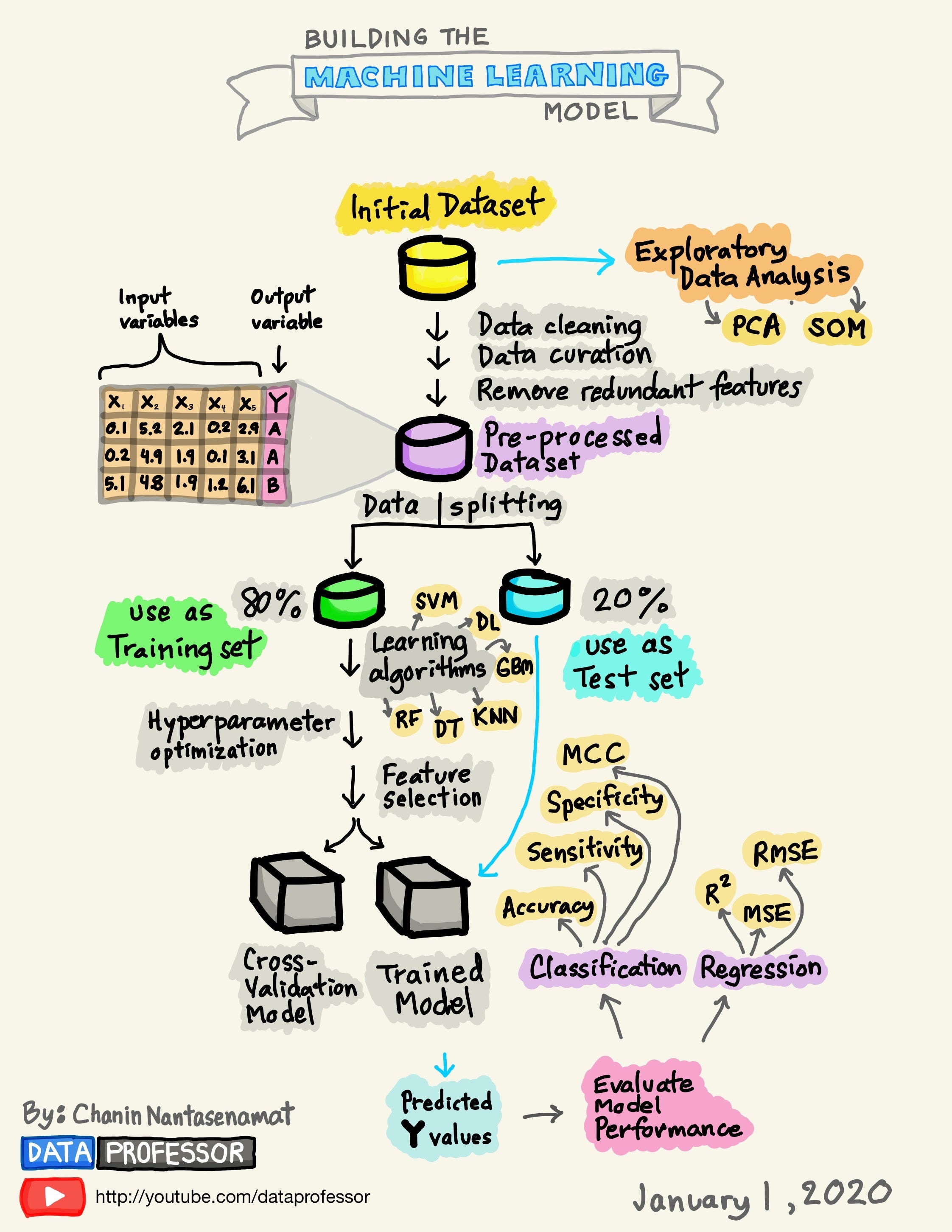
1st 문제 정의
2nd 라이브러리 및 데이터 불러오기 & 데이터 확인하기
라이브러리
sklearn
- sklearn.model_selection / train_test_split,KFold, GridSearchCV
- sklearn.metrics / accuracy_score,mean_squared_error,confusion_matrix
- sklearn.tree / DecisionTreeClassifier, plot_tree
- sklearn.ensemble/ RandomForestRegressor
3rd 전처리 / 피처 엔지니어링
전처리
1) 범주형 데이터 처리 방법 각 값들의 서열이 명확 → 숫자로 변경 okay ( 예외) 결정트리 사용시 트리가 깊어지면 범주형 데이터를 숫자로 변경해도 okay) 각 값들의 서열이 X → 범주가 적을 때는 더미 변수 / 범주가 많을 때는 범주형끼리 합치기
2)결측치 처리 방법
-
열 삭제
drop특정 변수의 대부분이(70~80%) 결측치일때 90%가 결측치라고해도 매우 중요한 역할이면 어떻게든 활용 방법 찾기 -
행 삭제
dropna()결측치 비중이 낮고 데이터 크기 클때 -
채우기
fillna()- 평균값, 중앙값,다빈도값 채우기
- 임의의 텍스트,숫자 채우기 ex) ‘unknown’, -99 ->트리 기반 모델에서는 큰 문제 X / 선형 모델에서는 데이터의 왜곡 불러올 수 있음
3) 스케일링
표준화 스케일링 StandardScaling데이터의 기존 형태가 사라지고 정규분포를 다르는 결과물- 아웃라이어의 영향 0
- 평균이 0이 되고 표준편차가 1이 되도록 데이터를 고르게 분포
최소-최대 min max scaling데이터 분포의 특성을 최대한 그대로 유지하고 싶을 때 사용- 아웃라이어의 영향 0
- 데이터의 기존 분포를 가장 있는 그대로 담아내며 스케일만 변화
- 범위는 0~1
- Robust scaling
- 아웃라이어 영향 X
- 데이터에 아웃라이어가 존재하고, 그 영향력을 그대로 유지하고 싶을 때 사용
정규화 Normalizer Scaling: 행 기준의 스케일링이 필요할 때 사용하거나, 실제로 거의 사용 X
피처엔지니어링
기존 데이터를 손 보아 더 나은 변수를 만드는 기법, 도메인 지식을 바탕으로 정확한 목적을 가지고 수행하는 피처 엔지니어링이 효율적
다중공선성
- 독립변수 사이에 상관관계가 높을 때에 발생하는 문제로, 독립변수 A와 B의 상관관계가 매우 높다면 y가 증가한 이유가 A,B 어느 것 때문인지 명확하지 않아서 데이터의 특성에 따라 결과가 달라질 수 있다.
- 선형 모델에서 주의!
- 해결 방법
- 상관관계가 높은 변수 중 하나 제거
- 둘을 모두 포괄하는 새로운 변수 생성
- PCA와 같은 방법으로 차원 축소
학습셋과 실험셋 나누기
나누는 이유? 학습에 사용한 데이터와 평가용으로 사용한 데이터가 동일하면 모델을 만들고 나서 새로운 데이터에 맞는지 검증할 수 없음
4th 모델링 및 예측하기
모델
| 모델명 | 장점 | 단점 |
|---|---|---|
| 📉 선형 회귀 보험료 예측하기 연속된 변수 예측 |
• 모델이 간단해서 구현과 해석이 쉽다 • 모델링 시간 짧음 |
- 예측력이 떨어짐 - 독립변수와 예측변수의 선형 관계를 전제로 하기 때문에 이러한 전제에서 벗어나는 데이터에서는 좋은 예측을 보여주기 어려움 |
⎇ 로지스틱 회귀 타이타닉생존자 예측 |
• 구현하기 용이 | 선형 회귀 분석을 근간으로 해서, 선형관계가 아닌 데이터에 대한 예측력이 떨어짐 |
🫧 KNN 와인등급 예측 다중 분류, 작은 데이터셋 |
• 직관적이고 간단 • 별도의 가정이 없음 |
• 데이터가 커질수록 느려짐 • 아웃라이어에 취약 |
÷ Naive Bayes 스팸여부 예측 독립변수들이 독립적이고 중요도가 비슷할 때 자연어처리 좋은 성능 범주형 변수 많을 때 적합 |
•비교적 간단한 알고리즘에 속하며 속도 또한 빠르다 •작은 훈련셋으로도 잘 예측 |
모든 독립변수가 각각 독립적임을 전제로 함, 실제 데이터에서 그런 경우가 많지 않음 |
🌲결정 트리 종속변수 연속형0범주형0 시각화 유용 |
• 별도의 가정이 없음 • 아웃라이어에 대한 영향을 거의 받지 X • 트리 그래프를 통해서 이해하고 설명 가능 |
• 트리가 무한정 깊어지면 오버피팅 문제 야기 • 예측력 떨어짐 |
🌲🌲🌲랜덤 포레스트 중고차 가격 예측하기 종속변수 연속형0범주형0 시각화 유용 이상치존재할때 |
• 아웃라이어에 대한 영향을 거의 받지 X • 선형/비선형 데이터에 상관없이 잘 작동 |
• 학습속도 느림 • 모델 해석 어려움 |
🌲🌲🌲XGBoost 커플 성사 여부 예측하기 트리 베이스 부스팅 기법 종속변수 연속형0범주형0 표로 정리된 데이터의 경우, 거의 모든 상황에 활용 가능 |
• 예측 속도가 빠르고 예측력 또한 좋다 • 변수 종류가 많고 데이터가 클수록 상대적으로 뛰어난 성능 • feature importance 계산 가능 |
• 하이퍼파라미터 튜닝 까다롭다 • 모델 해석 어려움 |
🌲🌲🌲 LightGBM 이상 거래 예측하기 리프중심트리 부스팅 기법 종속변수 연속형0범주형0 표로 정리된 데이터의 경우, 거의 모든 상황에 활용 가능 |
•XGBoost보다 빠르고 높은 정확도를 보여주는 경우가 많다 • 변수 종류가 많고 데이터가 클수록 상대적으로 뛰어난 성능 • feature importance 계산 가능 |
• 하이퍼파라미터 튜닝 까다롭다 • 모델 해석 어려움 |
하이퍼파라미터 튜닝
- n_estimators : 결정 트리 개수
- max_depth : 트리의 최대 깊이
- min_samples_split : 지정된 숫자보다 적은 수의 데이터가 노드에 있으면 더는 분류 X
- min_samples_leaf : 분리된 노드의 데이터에 최소 몇 개의 데이터가 있어야 할지 결정
- n_jobs : 병렬 처리에 사용되는 CPU 코어 수, -1을 지원하면 모든 코어 사용
Ensemble 앙상블
< 트리 모델 진화 과정 >
결정 트리 → 배깅 → 랜덤 포레스트(각각 트리 독립적)→ 부스팅→ 경사부스팅 → XG 부스팅
Voting 중
Hard voting은 ‘전체 훈련 세트 하나’에 대해 ‘여러 개의 분류기’를 훈련시킨 후 각 분류기의 예측을 모아서 가장 많이 선택된 클래스로 예측하는 방법으로, 이렇게 다수결 투표로 정해지는 분류기를 말합니다.
Soft voting은 모든 분류기가 ‘클래스의 확률’을 예측할 수 있으면 개별 분류기의 예측을 평균내어 확률이 가장 높은 클래스를 예측합니다.
Boosting은 약한 학습기를 여러 개 연결하여 강한 학습기를 만드는 앙상블 방법으로
AdaBoost은 이전 모델이 ‘Underfitting했던 training data’의 ‘가중치’를 더 높이며 새로운 모델 생성
Gradient boost도 동일한 방식이지만 가중치 대신 ‘잔여 오차’를 새로운 예측기에 학습
분류 평가
| 예측값 0 | 예측값 1 | |||
|---|---|---|---|---|
| 실제값 0 | TN 음성인것을 맞게 예측 |
FP 1종 오류 양성이라고 잘못 예측 |
— | |
| 실제값 1 | FN 2종 오류 음성이라고 잘못 예측 |
TP 양성이라고 맞게 예측 |
재현율 recall | |
| 정밀도 precision | F1 score |
설명력과 예측력
알고리즘의 복잡도가 증가할수록 예측력은 좋아지나 설명력은 다소 떨어지는 반비례 관계
- 예측력: 모델 학습을 통해 얼마나 좋은 예측치를 보여주는가?
- 설명력: 학습된 모델을 얼마나 쉽게 해석할 수 있는가?
- 어느쪽을 택해야 하는지는 상황에 다라 다르다
ex) 의학 계열에서 특정 질병의 발병률에 대한 예측 모델을 만들 때는 발병률을 높이거나 억제하는 중요한 요인을 밝히는 데 설명력이 좋은 알고리즘이 적합
ex) 사기거래를 예측하는 모델에서는 요인보다는 더 정확하게 사기거래를 잡아낼 수 있어야 하므로 예측력이 높은 알고리즘이 적합
5th 하이퍼파라미터 튜닝
엄청난 개선 X, 조금이라도 나은 모델을 만드는 역할
Grid Search
하이퍼파라미터 후보들을 입력하면 각 조합에 대해 모두 모델링해보고 최적의 결과가 나오는 하이퍼파라미터 조합을 알려줌 모델링 횟수 = 하이퍼파라미터 후보들 ( ex) max_depth X lr) X 교차검증